The literature on cognitive aspects of software engineering is sparse. The existing investigations stem mostly from cognitive science or Human-Computer interaction research and deal with psychological theories on the nature of programming. Unfortunately, not much of the available results has been used by software engineers to understand their very own task or to improve their tools. Why is this the case?
First, software engineering is often identified with the task of developing software. However, this is only one side of the medal. Actually, software engineering is a very general design task and the existing results for these tasks can be applied. Furthermore, software engineering is a very broad subject that is made up from several, sometimes independent, activities that deal with many different products besides the code of the respective software system. The following table shows a non-exhaustive list of activities that occur with a software engineering task and that deal with various (intermediate) products on different levels of abstraction. Before the interdependencies between these different activities can be structured into process models, it is necessary to understand these interdependencies on a cognitive level.
| domain analysis | code analysis | validation |
| code documentation | extension | architecture design |
| testing | reuse | user documentation |
| component design | refinement | coding |
| simulation | deployment | ... |
Second, software engineering is often identified with developing software. However, a major task of todays software engineers is to comprehend either software that was developed by other team members or existing, third party software. This topic will become more and more important in the future because software is used in almost any part of nowadays life and the effort to maintain this existing software already exceeds the effort to develop new software. Thus, it must be a goal to todays software engineers to develop tools and techniques that ease the understanding of newly developed software for future use.
The way in which human beings handle data about their environment and the internal processes that are performed during information processing are subject of research in cognitive psychology. In this section, I will briefly introduce some concepts and models that are needed later when the cognitive model of software engineering is presented.
The model of cognitive processes that is assumed in this chapter is based on the so-called Single-Store model of memory. This model views the human memory as single, coherent structure that consists of a collection of cognitive units that are linked in network-like manner. The network is organized as hierarchically ordered levels where the elements of one level are abstractions of the elements on lower levels. For example, on the lowest level of abstraction, the sensory information that are associated with a particular item are stored whereas on a higher level, a symbolic representation for that same item is used.
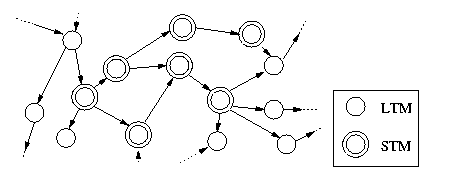
The Single-Store model distinguishes between two activation levels for each cognitive unit. The units with a low level of activation are kept in the long-term memory (LTM) that is used as a passive, permanent knowledge store with a potentially unlimited capacity. Every cognitive unit can enter the LTM, but no unit can leave it afterwards. However, some cognitive units may become irretrievable in the course of time which is commonly referred to as "forgetting".
Some of the units in the LTM may have a higher level of activation then the rest. These cognitive units are said to reside in the short-term memory (STM) of the individual. The elements of the STM are thus not spatially separated from the elements of the LTM (as it was assumed in older theories about the human memory), but rather differ from these only in their activation level. The major difference between the LTM and the STM is that the former has an unlimited capacity whereas the latter has a maximal size of approximately seven items. In the following figure, I have depicted a network of cognitive units out of which some are activated in the STM while the others remain passive in the the LTM.
Although the LTM has an unlimited capacity, the size of the cognitive units should be kept at a minimum in order to speed up the retrieval process. The major technique for data compression is called chunking where a chunk is a collection of low level units that belong to the same mental construct. Thus, several simple units are encoded into a single, new item that is expressed in terms of these simple units and in terms of other chunks. An example for chunking is that people remember words instead of syllables or letters or even phonetic impressions. However, the latter are linked to the higher level cognitive unit and can be accessed whenever necessary. Several studies have shown that chunking is a cognitive capability that has a large impact on cognitive performance. In one of these studies, novices and experts were asked to recall chess positions. While experts performed distinctly better on realistic game positions, the differences declined on random positions. The explanation for these results is that experts can compress more information into a single chunk then novices whenever they can use existing chunks such as sub-configurations on the chess board. A similar experiment has been reported where programmers are asked to recall Algol programs. Again, experts performed much better then novices on real programs but not on scrambled programs.
I have said before that the human memory is organized as in hierarchical levels of abstraction. While the representation of knowledge on low levels of abstraction is accomplished with little abstraction from the pure sensory impressions, knowledge on higher levels of abstraction is represented differently. Single cognitive units are represented in so-called schemata where a schema is a knowledge packet with a rich internal structure. Each schema consists of several slots (variables) that can be instantiated with slot fillers (values). Partially instantiated schemata are prototypes for a particular concept, fully instantiated schemata are exemplars of this prototype. These exemplars can be ordered according to their semantic distance to their common prototype.
In the software engineering domain, schemata can be classified according to three different classes. The first class are programming schemata that are either variable plans or control-flow plans. A variable plan, for example, contains the semantic knowledge about the concept of a counter variable that is used in loops and a typical control-flow plan is the programmers knowledge about the general process of iterating over list of arbitrary elements. In a real program, the software engineer will need both schemata (amongst others) to implement a concrete function e.g. to sum up a list of integer values.
The second class of schemata are application domain schemata that represent the engineers background knowledge about the application domain. It is a crucial task in the software engineering process to match the application domain knowledge and the programming domain knowledge in order to develop or to understand a software system for the application domain.
The third class of schemata, finally, are discourse schemata that enable the software engineer to reason and communicate about programs besides functional aspects. These schemata include knowledge about general principles and conventions such as the convention that a variable should reflect its function or that particular variable names are used for certain tasks (e.g. i and j are typical variable names for loop variables).
For larger units of knowledge with many different interrelationships, schemata are not suited because of their rather descriptive nature. A more dynamic approach to the representation of large-scale cognitive units are mental models. These mental models contain declarative and procedural knowledge about a well-defined field and are often individualized scientific theories, e.g. about electricity. Humans usually maintain a wide variety of these mental models and construct new models on demand, e.g. in the process of understanding the behavior of a complex system. The newly created models must be consistent with the existing models because these are resistant against changes and can only be revised with a certain learning effort.
A general design task is the process of arranging a collection of primitive elements according to a given design language in order to achieve a particular goal. Examples for general design tasks can be found in technical disciplines such as architectural design or electrical circuit design, but also in cultural areas, e.g. in music composition or in writing an essay. Thus, design tasks are complex tasks that entail multiple subtasks that draw on different knowledge domains and a variety of cognitive processes.
Although these subjects appear to be rather different in their nature, they nonetheless share two fundamental activities that are exercised during the overall design process. The first general aspect is composition, i.e. the process of developing a design by describing associations between the structural elements of the design. In terms of a software engineering process, this step maps what a program should achieve onto a detailed set of instructions that specify how these requirements are implemented in a particular programming language.
The second, and equally important aspect, is comprehension. Comprehension means to take a particular design and to understand the associations between its structural elements. The input for this process may be a design that was produced by a third party, but often it is a design that was developed by the same person. Now, why should it be necessary for a designer to understand something that he or she has developed? Simply because it is almost impossible to anticipate all implicit relations that are introduced as side-effects of one explicit design decision. For example, creating a new function for a particular purpose may have the side-effect that other, already existing functions can be simplified by using the newly created function. For the software engineer, the process of understanding a design is to map how a program implements a specification to what this specification entails.
Please note that the software engineering process for a particular software system can start with any of these two fundamental activities. When developing a new system, the engineer will start with the composition of an initial design that is then elaborated in the the course of the engineering activities. In the case of a maintenence task, on the other hand, the software engineer must first understand the existing software before changing it according to the new requirements.
The most important property of general design tasks is the evolutionary nature of the entire process. The design process is not sequential in that it proceeds from one intermediate product to the next until the design is completed, Rather, the process involves frequent revisions of previous decisions, re-structuring of the design elements or exploration of tentative solutions for particular sub-problems.
Therefore, the design process often starts with constructing a kernel solution and then incrementally extending this solution until it meets the initial requirements. In software development, the kernel solution is often retrieved by re-using existing code fragments and the applying a series of repeated modifications to these fragments until the target system is constructed.
Before I describe a cognitive model of software engineering activities, I will outline a fundamental difficulty that is associated with the general task: the dichtonomy of the object that is worked on.
On one hand, we have a concrete design that is given in some external representation and that is manipulated by the process, e.g. the code of a software system, the draft of an essay or a piece of rock used by a sculptor. In the case of a software system, the design is often given in several external representations as shown in the following figure.
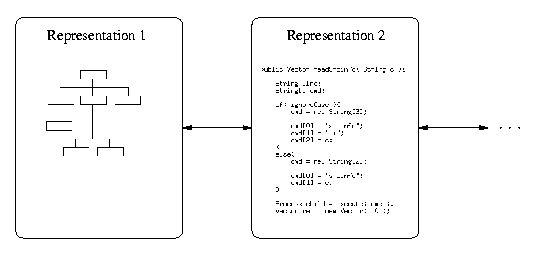
Ideally, these different representations are semantically isomorphic and differ only in their external form although in practical situations it is a major problem to keep the different representations synchronized. For the moment, however, we will not consider this problem and assume that the external representations are always consistent.
Besides the concrete design, we have the model (or the idea) inside the designers head that captures the intention of the final result of the design process as well as the the current state of the design. As shown in the next figure , the designer uses the state model and the goal model to derive a plan to reach the goal from the current state.
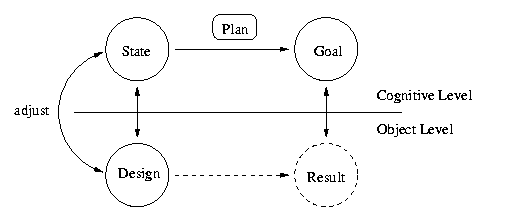
But even if we assumed that there is an error-free plan that transforms the current state into the goal state, the result will not be as as expected. Why? Simply because the designers model of the current state does not correctly reflect the current state of the design. Ideally, these two objects should be isomorphic, but in the real world, there are so many details to consider that a true isomorphism will hardly be achieved. Because of this problem, the aforementioned comprehension process is crucial for the entire design task. It guarantees the necessary adjustment of the cognitive model in the designers head and the concrete design that is worked on. The goal of this comprehension process is to approximate existing mapping between the design and the model as close to an isomorphism as possible. The better the concrete design is understood, the better will be the result.

The cognitive model of software engineering that is presented in this section consists of three distinct layers as shown in the preceeding figure: the cognitive layer is the highest level of abstraction and operates on the various knowledge sources of the individual. The first of these knowledge sources is the background knowledge that contains general knowledge about computers and computations and technical aspects such as programming languages or hardware. Second, the cognitive layer also contains the engineers knowledge about the application domain for which a new software system is developed or where an existing system comes from. This knowledge is a crucial factor for the success or the failure of a software engineering task because it determines the bounds into which the software engineer can apply his or her technological abilities. If the problem domain is not sufficiently understood, the results will seldom match the intentions of the customer. Obviously, it is impossible for a software engineer to be an expert in any possible application domain and so the domain knowledge of the software expert develops during the design activities. The resulting implicit models must be evaluated against reality by external supervision of a domain expert in order to detect misconceptions.
Besides these major information sources, the cognitive layer also contains a mental model that has the same functional nature and structure as the system it models. This mental model is used for the simulation of processes within the real system and to develop and (pre-)evaluate hypothesis about the systems behavior. The information structures with the cognitive layer are usually not represented explicitely. They are the sum of experiences of the engineer, often over years, and are thus hard to capture in an explicit form that can be communicated across individuals.
On the intermediate layer, the system is represented more technically in terms of the background concepts and the domain knowledge. This layer can be supported by an external representation although this is often omitted. If an external representation is used, software engineers tend to use highly individualized pseudo-languages. These pseudo-languages are usually a collage of of convenient formal or informal notations from several fields where each notation is selected on the basis of suitability for a particular task. The different notations are often partially inconsistent which makes it difficult to develop a general transformation scheme from the intermediate representation to a particular target language. This transformation process is therefore usually done manually. The intermediate layer is particularly important as it dictates the quality of the resulting design because it has been shown that the programming language has only a weak influence on the solution.
The lowest layer, finally, is the implementation layer that contains the code that is understandable by a computer. Obviously, the information on this layer must be encoded in an external form with a fixed syntactic format. In the usual software engineering practice, the communication across individuals takes place on this layer because of the standardized access to the information structures. The problem of this practice is, however, that information is lost during the transition from the intermediate to the code layer. Only particular associations between structural elements are transformed while others are lost and must be re-built by the receiver.
Each of the above layers is subject to resource limitations that restrict the possible input and output of the process on a particular layer. Examples for these constraints are cognitive resources such as the cognitive capacity which was already discussed in the Introduction or knowledge resources e.g. about the application domain or in terms of problem solving knowledge such as syntactical knowledge about the programming language or appropriate design patterns. The third form of resource limitations are technical resources which includes the expressive power of the programming language or tool support on the code level.
The information that is handled in each of these layers is provided as flexible information structure that represent the structural elements as well as their relationships. The most interesting property of the information structure is the flexibility in which the elements can be arranged. It is therefore possible to re-arrange the structure of the problem and solution descriptions according to the structure of the underlying task.
A good means to represent the structural design elements is provided by schemata as they were introduced above. Schemata are the basic elements for data generation, acquisition and manipulation that can be used in different ways. In the forward use, existing schemata are instantiated with problem related information in order to construct a concrete solution from abstract solution plans. The other form of schema usage is the analytical backward use where schemata are used to recognize particular aspects of the system and to either construct new schemata that describe these aspect or to instantiate existing schemata in the course of program understanding.
To illustrate the different layers that work together in the course of software engineering activities, consider the following example. A program for graphical manipulation of simple objects must be developed in a assembly language for an embedded system. On the cognitive layer, the engineer deals with concepts such as lines, squares or circles and their interrelationships. Assume further, that a particular function of the system requires to compute the diameter of a circle from the area it covers on the screen. On the cognitive layer, the engineer will combine this (domain) requirement with the background knowledge about geometric objects and retrieve the matching formula for the space of a circle from memory and rewrite it so that it yields the desired result (the diameter). On the intermediate layer, this formula is used directly, probably by incorporating it into an external representation of the problem solving attempts of the engineer. In the subsequent transformation process, the elements of the formula are then broken up into parts that need no further refinement (e.g. division) and those aspects that are not provided by the underlying programming language and therfore need an explicit implementation (e.g. the square-root function).
We can already tell from this tiny example, that a lot of information is lost down along the line from the cognitive layer to the code layer. This gap widens as system gets bigger and it is the task of a software engineering support system to minimize the information loss as far as possible.
A general design task as it was described above is an iterative, explorative process that usually starts with a fuzzy specification of a complex goal. A cognitive model for working on these kinds of tasks was also presented above and some issues regarding knowledge sources and knowledge representation were discussed. In this section, I will combine the introductory remarks of the previous sections into a generic process model that describes the general steps in building or in understanding a design.
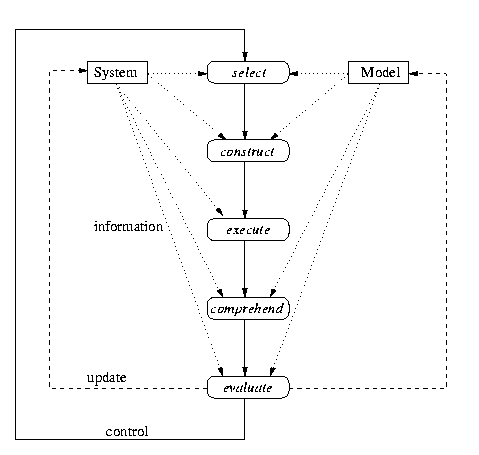
The above figure shows process model that consist of six steps: In the first step, the objective of the following iteration is selected. This can be a concrete entity such as design element that needs further elaboration but it can also be an abstract property or a functionality of the system that is to be analyzed for the purpose of understanding the property or functionality itself as well as its relation to the entire system. Then, either a solution for the sub-problem or a hypothesis to test the assumptions about the system is constructed. Note that different solutions for a particular problem may be tested and compared in subsequent iterations. After that, the solution is implemented or the test case for the hypothesis is run on the system. Then, the consequences of the implementation or the results of the test case must be understood before they can be evaluated according to given quality measures or test case specifications. After the evaluation is completed, a new iteration starts. In the above figure, the steps of the process are shown together with the inherent flow of control and information. The six steps are summarized to:
To illustrate the generic process model, consider the task of understanding an existing program that implements a graphical editor. In the first step, a typical sub-problem of this task is identified e.g. to understand how a newly created element is integrated into the internal data model of the editor. Thus, the question to answer is "Which data stores are used and how is the new element linked to existing elements?".
In the second step, an hypothesis is created on the basis of the present code. The engineer may, for example, select several variables whose names suggest that these variables are involved in the process, e.g. a variable elementList would be a good candidate. Then, a test case is developed that generates a new element that is passed to the system. The major difficulty in developing test cases in general is to focus on the aspects in question and to leave the rest of the system untouched. During the test case specification, the expected results - based on the assumption that the hypothesis holds - are defined as well.
In the next step, the test case is run and the results are recorded. Running the test case may become a nontrivial task if the system requires some complicated start-up procedure before it is in the state to accept a particular test input. Especially distributed systems are sometimes difficult to bring to the desired start state.
The fourth step of the cycle is to understand the changes that occurred within the program. These changes are retrieved by a before and after analysis of the relevant aspects of the system. The relevance of particular aspects is usually given by the hypothesis that was defined earlier.
In the evaluation step, the results are checked for compatability with the expected results on the hypothesis is accepted of rejected on the basis of this evaluation process. A third possibility for the result of this evaluation is that the data is not sufficient to allow for a decision on the validity of the hypothesis and that additional test case are necessary before a decision can be made. After these steps have been performed, the process iterates back to the beginning to start a new cycle.
The basic engineering cycle that has been presented in this section is only a very general framework for engineering tasks. A concrete instantiation of the generic model usually depends on a specific application area such as civil engineering or, in our case, software development. Each of these application areas has some special skills that are necessary for a successful application of the basic engineering cycle. In the following section, I will therefore outline some of the basic skills that are relevant in the software development domain.
In this section, I will give a brief overview over technical skills and possible development strategies that have been identified as being relevant for the software development process. The following paragraphs are a loose collection that I have compiled from several sources and that I think capture the most relevant skills and strategies for software engineers. Thus, the reader should be able to recognize some of his or her own habits in this section. In the course of the section, we will start out with an overview over (generic) development strategies and then proceed with a list of individual skills that are more or less necessary for a successful software engineer.
Development strategies capture how individuals proceed with the engineering tasks on a particular subject, i.e. they describe, in terms of the basic engineering cycle that was presented in the previous section, how the next sub-problem is selected. These strategies can be explained at hand of an n-ary tree as shown in the following figure that describes the current state of the design at different levels of abstraction.

However, the implicit assumption of this view is, that there exists a unique starting point of the design process, indicated by the root of the tree. In previous sections, I have argued that the information about the system that is used by the engineer is more likely to be represented in a flexible, network-like structure. This idea is consistent with the wide-spread view that "real systems have no top", i.e. there always exist a large number of perspectives on the same system. Therefore, I suggest that there are multiple design trees that are projections of the net with respect to a particular relationship of the structural elements. Thus, as shown in next figure, we may have the refinement-tree that represents e.g. the refinement of system elements or we may have the uses-tree that describes the functional dependencies between design elements.
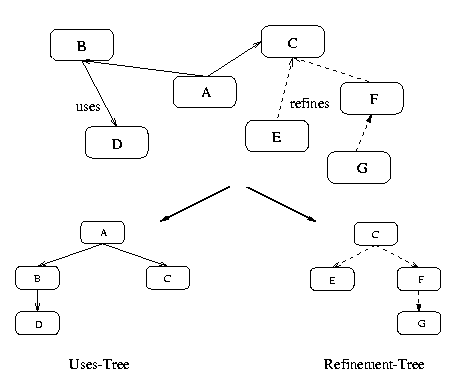
The strategies that are discussed in the following paragraphs are used in two ways: first to select the relation (and therewith the respective design tree) that needs further expansion and second to select a particular design element within the design tree that is to be worked on next.
In using a top-down strategy, the designer proceeds from the structural elements on the most abstract level to more concrete elements until finally the code level is reached. This strategy is very common with imperative models of computations (and sometimes in later phases of object-oriented approaches) and it is more or less formally capture in so-called Structured Programming approaches. This strategy is usually most appropriate whenever the designer is familiar with the problem domain and thus knows in advance what potential difficulties lure on lower levels of abstraction.
A bottom-up strategy, on the other hand, starts with a collection of low level design elements that are subsequently assembled into bigger units. This strategy is quite common in functional or declarative models of computations such as Lisp as well as in early phases of object-oriented programming. An advantage of this strategy is that it can be used to detect implementation problems that can force a re-design on higher levels of abstraction to match the requirements of a particular platform.
The top-down and the bottom-up strategy describe how to proceed from one level of abstraction to the next. These strategies can be combined with another two strategies that prescribe when to proceed from one level to the next.
In a breath-first strategy, all design elements on one level of abstraction are developed before the next level is approached. This strategy is therefore particularly helpful to deal with interactions among design elements on the same level of abstraction. However, the problem is that these interactions can become too complex to be simultaneously considered by the designer. Thus, a pure breath-first strategy is usually not feasible.
A depth-first strategy, on the other hand, aims at developing components of one or few branch(es) to their full depth and then going back to the highest level of abstraction to start with the next branch(es). This strategy is very good to explore particular aspects of the design in early stages of the design process and to develop alternative solutions for a particular problem.
The four strategies the have been discussed in the previous paragraphs are idealized and abstracted. In a real design task, none of these strategies is applied throughout the full development process. Rather, the developer usually chooses the best strategy for the next few steps. This behavior is called opportunistic.
In an opportunistic strategy, the next sub-task is selected according to its utility and its cognitive costs. If the information for handling the current design element is not available, the processing is postponed if the retrieval would be too costly (or impossible, because necessary other design elements are not even built). In this case, other design elements are expanded because it is "cheaper" then sticking to the plan which would dictate a context switch. Thus, an opportunistic strategy needs support for flexible switching between different task. We will return to this aspect later when we discuss tool support requirements for the software development process
Besides these development strategies, which obviously influence the overall "flavor" of the engineering process, we have some other important skills that are used by the software engineer. One of the key capabilities of a successful software engineer is the ability to use abstraction. Abstraction (sometimes also called modeling) is the process of deriving the general from the specific while leaving out unnecessary details. An important abstraction technique is layering, i.e. the process of decomposing the target problem into several, hierarchically related sub-problems where the sub-problems on a lower layer are refinements of those on higher layers. The problem of this technique, however, is to decide when to stop the decomposition in order not to run into a too detailed analysis.
Another important capability is structuring, i.e. the aptitude to define the relation between the whole and the parts as well as between the parts themselves. Structuring is closely related to abstraction in that it tries to find a reduced representation of a complex system such that the basic character is revealed. We can distinguish between static structuring where the resulting structure remains fixed over the system lifetime and dynamic structuring where the structure can change during the system lifetime. A sub-category of structuring is the ability to build hierarchies by ranking, ordering or graduation of the parts of the system. Also related to this selection of capabilities is grouping or modularization. Ideally, the system is divided into self-contained functional groups that can be worked on in isolation whereas in reality, existing dependencies blur the ideal picture and require to model dependencies explicitly. Therefore, the designer must be able to identify and describe these dependencies in lucidly. Thus, the designer must have extremely good communicative skills and posses means of verbalization in order to express thoughts and ideas to bring them to his or her own as well as consciousness to transport them over boundaries of individuals. Thus, verbalization is very important for internal reasoning as well as communication between engineers.
Besides this list of quite general capabilities, there are a number of aspects that are specific for the software development process. Simulation, for example, is referred to as the process of mentally imitating the system behavior on the basis of the mental model that is constructed in the design or comprehension process. It can be used to predict potential interactions between design elements or is can be used in an opportunistic strategy to select the design elements that need expansion. Furthermore, simulation can support the comprehension process by using the mental model of the system to develop the expected results of a particular hypothesis before it is tested on the system. Simulation is also useful to roughly evaluate tentative solutions for a particular problem prior to implementing it. This is sometimes a cost-effective way to detect misconceptions before they are introduced into the system.
Another important aspect of software engineering is the change of perspective. Thus, the engineer can either take the perspective of the user for a better understanding of the requirements or he or she can take the users perspective to develop hypothesis about the systems external behavior. Furthermore, the engineer can switch to the perspective of another software engineer in order to assess the structure and the comprehensibility of the current design. This can help to improve the maintainability of the final design.
The last important skill that I want to mention in this non-exhaustive list is to make use of existing experience and software design re-use. It is empirically validated that any software design is seldom generated from scratch. Rather, the designer usually makes use of existing designs that are adapted to the current requirements. These design templates are either retrieved from the designers internal database, i.e. from memory, or they are take from external sources such as the GoF book. Such re-use of working solutions is crucial for developing a design in always decreasing product life cycles.
In this section, I have briefly outlined some basic cognitive skills that are relevant for the software developer. The application and development of these skills can be greatly simplified by the use of adequate tools and methods that support the software engineer in his or her work. In the next section, I will therefore sketch some general requirements for such tools or methods.
In this section, we will discuss some aspects that should be addressed by software engineering design tools or methods that are constructed according to the cognitive aspects that were presented in the previous sections.
The first major requirements deals with the presentation of the current state of the design. The presentation scheme of a tool or method should support a broad range of perhaps individualized notations. It should allow the designer to express his or her ideas in the most suitable form without imposing a particular syntactical structure. Experts want a notation scheme that allows them to express their ideas elegantly and therefore often use individualizes schemes that were discussed earlier. Obviously, this requirements has the consequence that automatic tool support is difficult or even impossible. I will argue later, why the basic idea of individualized notations is still feasible although it requires some additional start-up effort from the designer. The second important aspect in conjunction with presentational issues is that a tool or method must support perceptual support for the contents of the design. For example, useful information should be highlighted and the information should be represented in redundant perceptual and symbolic forms. The information presentation should also support revelation, i.e. it should reflect the structure of the solution and perhaps the process that lead to the current state of the design. To document the evolution of the design to its current form can especially help an engineer to understand the design from a third party. Finally, the presentation scheme of a tool must support grouping mechanisms, i.e. strongly related components should be kept together. The difficulty with this requirement is that the term "strongly related" depends on the current focus of the engineer. Therefore, it is necessary to support dynamic re-ordering of the information structures according to the change of focus.
The literate programming approach proposed by Donald Knuth is a good example for the idea of grouping related aspects together in order to make them accessible to the programmer. The problem of literate programming, however, is that the relation between the parts remain static and thus prevent the programmer from choosing the most adequate relation for a particular situation.
Presenting information statically, however, is only one side of the medal. An equally important aspect that requires tool support is the navigation within the information structure that describes the current state of the design. Navigation through this information structure should be possible along various threads such as control flow, logical grouping, refinements etc. The navigation must be possible across levels of abstractions because expert software engineers want the ability to work with high-level constructs on abstract models as well as the ability to work on a low level such as hardware devices. The navigation should be supported by additional cognitive aids that ease, for example, simulation of the systems behavior by providing mnemonics for variable values or that allow for symbolic execution of the program as demonstrated. Finally, the navigation between different tasks should be backed by mechanisms for the management of the working memory, e.g. in case of an opportunistic refinement strategy by keeping a list of postponed sub-tasks.
The third major aspect besides presentation and navigation is changing the information structure that captures the current design state. Therefore, the presented information should be editable wherever it is presented, i.e. there should be no read-only presentations. Furthermore, any changes that are made to the design should be easily revisable and a tool or a method in general should not force premature commitment as it is often the case with existing development suites or methods.
The last major requirement for tool or method support, finally, is that the information structure that is developed in the course of the design process is accessible on a technical level. Expert software engineers expect to build their own tools because understanding the difficult mechanisms of a particular Software Engineering Environment is usually considered to entail more work then building utilities up from a low level. This easy access to the information structures then solves the above problem in conjunction with individualized notation schemes. The software engineer can build his or her own set of tool that transform the individual notation scheme to a particular target language and so express the design in an individual notation that is subsequently transformed into the target language. Although the initial effort to build the transformation tools is quite high, it quickly pay off because of the better internal management of the design object.
A good starting point for the development of tools and methods for software engineering, is to have a general model of the underlying process. Therefore, we will now skip our reflections about engineering in general and the required cognitive capabilities and address ourselves to the peculiarities of software development by starting with a general model of the software development process.